
Are You Breaking the Law When Using Web Scrapers?
What is web scraping?
Web scraping is a technique that automates gathering significant amounts of data from a website in real-time without the need for a massive roll-out of hardware. Typically this data exists as an unstructured HTML. Web scrapers convert this raw and unorganized information into a structured format, such as a spreadsheet or a database, to make it more accessible.
Is it illegal to use a scraper?
In short: it is perfectly legal as long as you're collecting data that is publicly available on the Internet. However, be cautious when working with certain types of information. Personal data, intellectual property, and confidential stuff are all protected by international regulations. This article covers all these aspects, so don't worry. Everything will be explained.
Now, on to the details:
When we start unpacking the legal side of any phenomenon, it's usually a breeze if it has a long history. For example, if it was mentioned countless times in the laws, backed by many court rulings, official explanations, and tons of fancy scholarly works. But scraping doesn't quite fit that mold. Lawyers that lived 100 years ago had no clue about it, the laws don't directly address it, and there's a serious scarcity of court cases and academic papers on the subject. The best approach is to contemplate which existing legal principles could potentially be applied to scraping and how they might be relevant.
In many countries, the laws imply that every individual has the fundamental right to seek and receive publicly available information through lawful means freely. But here's the burning question: is it truly as simple as it sounds, or is there more to the story?
Is data scraping legal in the EU?
In the European Union, text and data mining is allowed by using automated analytical methods to analyze digital text and data to generate information such as patterns, trends, and correlations.
The last phrase is a significant deal. It means that scraping copyrighted content is only okay if you use it to generate information. So, for example, you can scrape a webpage to get prices or analyze books for some language analysis magic. But you can't scrape news articles and go on to publish them on your own website. Also, remember that you can only scrape stuff you can access legally, like publicly available data.
Furthermore, the content owner may explicitly forbid scraping their content in a machine-readable format. While the EU law does not provide specific guidelines on the structure of a machine-readable format, it is generally understood that website owners can utilize robots.txt (we will explain it further). If the URLs you intend to scrape are listed as disallowed in robots.txt, you better steer clear. Otherwise, you're walking on the thin line of potentially violating the owners' copyright.
In other words, if robots.txt gives the green light to your robot, you can scrape. Regarding the legal side of things, the status of robots.txt is hazy. On the one hand, this file indirectly hints at the website owner's intentions. On the other hand, it's all in a language only machines can understand, making it quite a challenge to consider it a "contract in writing" (at least for now).
Is scraping data legal in the US?
In the USA, the legality of web scraping is somewhat similar to the European, but with a few points to note. There are several conditions that your data collection activities should comply with:
First, give the content a makeover: transform it into something new and meaningful before posting it to your website. Don't just copy and republish the original stuff!
Second, don't be a copycat: avoid creating a competing product. It's usually okay to scrape offers and promotions for some data crunching, but don't publish them on your website as is.
Third, keep it small: try not to copy a huge chunk of the original work. If you don't need specific data, skip it and save yourself some trouble.
What is robots.txt in scraping?
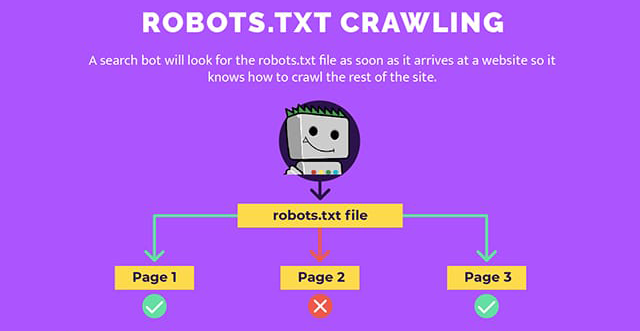
Since we mentioned robots.txt, let's go into detail about it. This file guides crawlers, telling them which URLs they can access on a website. Its primary purpose is to prevent a website from getting overwhelmed with requests.
The instructions in robots.txt cannot force crawlers to comply. Of course, search engine bots, like Googlebot, tend to follow the rules, but other self-made scrappers may not care. Additionally, different crawlers interpret the syntax of robots.txt in their way. Therefore, to guarantee effective communication, website owners need to address different web crawlers correctly, as some may not understand particular instructions.
So, adhering to the guidelines specified in robots.txt is crucial to ensure legal compliance while scraping. These rules clearly define what actions are permissible and what should be avoided. So, follow the robots.txt rules and respect the terms outlined in your activities to avoid web scraping legal issues.
What property damage can cause data scraping?
Now, let's add some intrigue. You might be scratching your head, wondering how property damage may be connected with scrapers. Hold on tight because this perspective is more plausible than it seems. While we usually think of information, websites, and programs as intangible entities, remember the robust servers that power them. These servers are very much real and tangible. So, if excessive scraping wreaks havoc on a server, we can actually talk about property damage.
Okay, okay, I'll admit that a full-on server meltdown is quite rare. But scraping can still pack a punch regarding financial losses for website owners. For example, imagine an online store bustling with customers ready to make purchases. But suddenly, due to excessive scraping, the website crashes and goes down for a good five hours. During that time, customers are unable to place their orders. The website owner is left counting their lost profits.
Of course, you may think: "come on, are you telling me that these servers, designed to handle heavy-duty tasks, can't handle a couple of self-made scrapers cooked up by a couple of nerds?". Well…it depends on the nerds and the servers.
Chronicles of the past:
Back in the days when servers were not as mighty, the idea of causing real damage seemed more within reach. In the late 1990s, one company decided to scrape eBay. Things escalated quickly! eBay took them straight to court, arguing that this company's parsing activities were going off the charts. We're talking about a whopping 100,000 daily requests, accounting for 1.5% of the website's traffic. Can you imagine? The strain on their servers was no joke, leading to unforeseen expenses for maintenance. Fortunately, the case eventually found its resolution through a settlement agreement.
Now, back to the nowadays, here's the big question: can the owners seek compensation for such losses? It's not as simple as clicking "add to cart". They need to navigate a few hurdles to make a solid claim. They have to prove four crucial elements: first, that an offense took place; second, that harm was done; third, that there's a clear cause-and-effect link between the offense and the harm; and fourth, that the party responsible is at fault. It's quite a challenge to tick all those boxes.
So, you see, property damage and financial losses from scraping can lead to unexpected consequences.
Criminal liability
Yes, you heard me right. Data collection could potentially lead you straight to jail. It may sound unbelievable, but there is potential for this. Imagine this scenario: you come across a password-protected website section, and your trusty scraper manages to crack the code. Well, that can be perfectly called "Unauthorized access", and it's no joke. In the United States, scraping has been known to land people in hot water, with cases falling under the Computer Fraud and Abuse Act (CFAA). This act deals with the punishment for unauthorized access to computer information, and it has sparked a fierce legal debate about what truly constitutes unauthorized access.
Courts have drawn analogies to "breaking" into a home, suggesting that unauthorized access involves bypassing defenses. So, if you're thinking about cracking passwords to get the needed info, think again. The CFAA might come knocking on your door. But wait, there's more! The creation and distribution of malicious software could also come into play regarding scraping legality. If you're using specialized software designed to copy computer information without permission, you might also face some legal consequences. Now, let's not hit the panic button just yet. The risk of criminal liability for data gathering may not be sky-high. After all, the laws were primarily created to combat hackers and virus writers, not those who gather data from websites. Also, the "victim" of your activities may want to avoid the hustle. They might find it easier to ban you for violating their user agreement than to spend money on courts.
Violation of user agreement
Here's where things get interesting: some websites have user agreements. These documents are tucked away in the footer that nobody really bothers to read. They contain all sorts of rules and restrictions, including a possible prohibition on scraping. So, if you're scraping in defiance of the user agreement, you're breaking the website's rules. But what does the law have to say about it?
User agreements are like contracts, and contracts are meant to be upheld. Therefore, failure to comply can lead to civil liability. But wait, is there really a valid contract in the first place? Contracts require your consent, typically indicated by signing or agreeing to the terms. But, when we visit a website, we rarely sign anything. Sure, we might click "OK" on those GDPR or Cookie notifications, but that's not the same as a user agreement. The actual user agreement is usually tucked away somewhere in the depths of the website, unseen and unnoticed. And if we simply browse the website without registering, no one even informs us about the terms of use. So, do we really have to follow them?
Types of online agreements
Click-wrap is when you actively agree by clicking a button or checking a box saying, "I agree to the terms". It's relatively straightforward.

With browse-wrap agreements, the terms are somewhere on the website, and it's up to you to find and read them. To form a contract, both parties need to express their consent. It's hard to know if you've consented when the agreement is just lying around on the website. So, unless there's some solid evidence to prove otherwise, it's tough to argue that a contract has been established. No contract, no obligations.

If you're scraping as a registered user, things become smoother. When you sign up, you usually agree to the terms of use. If those terms prohibit scraping, the website owner can enforce the sanctions outlined in the contract. As we discussed before, most website owners will impose the simplest sanction: a ban, which could mean suspension of services or termination of the contract altogether.
So, it's essential to know the user agreement and the consequences of scraping against its terms.
Intellectual property: the legal minefield
Is scraping websites legal in terms of intellectual property?
Well, intellectual property includes many things: works of science, literature and art, computer programs, databases, inventions, trademarks, know-how, and a dozen other different objects. So when you scrape, you often find yourself dealing with works of science, literature, art, and the notorious databases. Let’s review each of them:
General content
Website content like texts, photos, audio, and video sometimes fall under copyright protection. Just by existing, these works are automatically safeguarded by copyright law. So, when you scrape, you're essentially making copies of these works - a legal term known as "reproduction" of intellectual property. Reproducing copyrighted content without the author's permission is prohibited.
Open licenses
Of course, there's a glimmer of hope if the content is distributed under an open license like Creative Commons. In that case, scraping might not violate copyrights, as copying is explicitly allowed. However, not everything on the Internet is covered by an open license. Just because something is in the public domain doesn't mean it's not copyrighted. In fact, the general rule is that content is always copyrighted unless explicitly stated otherwise.
Not copyrighted content
As I mentioned earlier, not all content falls under copyright protection. For example, news reports, exchange rates, stock market data, weather forecasts, match results, sale announcements, and prices of goods are generally considered non-copyrightable!
Databases
Brace yourself for confusion, as the legal definition of a database differs from what you know in the programming realm. In legal terms, a database is a collection of independent materials systematically organized for computer retrieval and processing. While many technical databases may fit this description, the crucial point is that the law doesn't care whether it's PostgreSQL, Redis, Hadoop, an Excel spreadsheet, or a series of text files meticulously arranged in folders. If it's a collection of independent materials that can be processed on a computer, it's a database. So, even if the contents within the database are not individually protected, the database itself can be considered intellectual property.
There are creative and investment databases:
Creative databases are those where the creator has applied an original approach to selecting and arranging materials, transforming them into a work of art. Picture a website curated by a passionate individual, meticulously categorizing and tagging the works of ancient philosophers.
Investment databases are less about creativity and more about amassing a vast collection of materials or facts. But wait, there's a twist! Copyright law says that facts cannot be protected because they aren't considered original works of authors but mere observations of reality. So, when it comes to scraping facts like stock prices or weather data in the United States, you can breathe easier, as copyright concerns are less likely to rear their ugly heads.
However, things have taken a turn in the European Union, where the rules surrounding databases and facts are more complex. There is a legal provision for the protection of databases, which extends to the protection of facts if their collection, verification, or presentation requires a significant investment. This means that if someone has invested considerable effort in compiling a database, you cannot simply copy and use its contents. Therefore, if you scrap factual data within the EU, ensuring compliance with the abovementioned requirements is essential.
Is data mining illegal for personal data collection?
Initially, it is crucial to consider the relevant regulations based on your location and the location of the individuals whose data you intend to scrape. Depending on the jurisdiction, you should refer to the General Data Protection Regulation (GDPR) for the European Union, the California Consumer Privacy Act (CCPA) for the United States, or other applicable regulations in other locations. While collecting personal data might be permissible by default in certain countries, you need to receive explicit permission from the person to collect their data in other regions. So, collect personal data only if you really need it.
Personal data is defined as "any information relating to an identified or identifiable natural person". Therefore, any data that pertains to a specific individual can be considered personal data. This includes but is not limited to names, surnames, dates of birth, addresses, phone numbers, social media profiles, IP addresses, shopping preferences, gender, religious and political beliefs.
Is scraping legal for gathering publicly available personal data?
Many people in the web scraping community believe that only private personal data is protected, leaving publicly accessible data fair game for scraping. However, the permissibility depends on the applicable regulations.

GDPR
With the GDPR, all forms of personal data are safeguarded, regardless of the source. So, collecting personal data from public websites falls under its protection. In other words, it is illegal to scrape the personal data of EU residents.
CCPA
On the other hand, the CCPA takes a slightly different approach. It considers information provided by the government, like business register data, as "publicly available" and, therefore, not subject to protection. Furthermore, if an individual has willingly shared their data and made it public beforehand, scraping it from platforms such as LinkedIn or Facebook is allowed under CCPA. However, remember that this provision currently applies only in California, although we might witness other US states modifying their privacy legislation in a similar vein.
So, the permissibility of scraping publicly available personal data depends on the regulations at play, with GDPR safeguarding all personal data and CCPA allowing the scraping of certain publicly disclosed information. Therefore, staying informed and compliant with the laws governing your jurisdiction is crucial to navigating this complex terrain responsibly.
***
Summary
In conclusion, let's reflect on the legal aspects of web scraping we explored. I hope we have shed some light on the prohibitions and risks of the legality of scraping.
As a general rule, in many countries scraping falls within the boundaries of the law, saying that everyone has the right to gather information through lawful means, which includes web scraping. However, it's crucial to note that this general rule has numerous limitations and nuances.
Sometimes, these limitations lead to explicit bans on scraping in certain contexts. Other times, they introduce additional complexities and requirements that need careful navigation. Additionally, the legality of data collection can vary depending on the specific circumstances surrounding the data being web scraped.
Understanding the legal landscape of web scraping requires a nuanced perspective, acknowledging the general rule of legality and the specific limitations and conditions that may apply. By staying informed and mindful of these intricacies, we can engage in scraping activities responsibly and in compliance with applicable laws.
FAQ
What kind of web scraping is legal in the USA?
Web scraping is indeed legal in the United States. This conclusion has been bolstered by a recent court ruling reaffirming the legality of scraping publicly accessible data on the Internet. This decision is particularly significant for academics, researchers, and journalists who rely on scraping tools to gather information that is openly available online. However, it's still essential to adhere to specific guidelines. For example, avoid scraping data protected by the law: personal data, copyrighted content, or data not intended for public access.
What is the legality of scraping an API for commercial use?
When dealing with APIs provided by specific websites or services, it's crucial to consider their terms and conditions. As mentioned earlier, these terms govern the usage of the APIs. While some APIs may permit commercial use with proper attribution, it is always wise to thoroughly review the user agreement before proceeding.
Is scraping LinkedIn public data for data analysis legal?
Scraping LinkedIn public data for data analysis is, indeed, legal! Thanks to a groundbreaking decision by the supreme court, the long-running battle between HiQ (the scraping company) and LinkedIn has shed some light on this matter. The court's ruling emphasized that website owners' unilateral bans on scraping activities work against the public interest. Platforms like LinkedIn keep a lot of personal data, much of which doesn't even belong to them, and then use it to establish their information monopolies. This decision serves as a victory for those who believe in fair access to data and challenges the status quo. So, if you're keen on utilizing LinkedIn's public data for your data analysis endeavors, you can rest assured that you're on the right side of the law (just don't forget about laws governing personal data in different countries).
Is it legal to scrape Facebook?
Facebook is clear about its stance on scrapers. In their robots.txt file, you'll see that they explicitly disallow any scraping activity. Their scraping terms and conditions also mention in bold letters that "You will not engage in Automated Data Collection without Facebook's express written permission”.
However, even with these restrictions, you could still give scraping a shot, but let's be honest here. Just because you can, doesn't mean you should.
Besides the legal concerns, fetching data from Facebook may become quite an ordeal. As mentioned above, though Facebook prohibits all automated crawlers, scraping data from the website is still technically possible. Are web crawlers legal? Yes, they are. But the problem is that Facebook won't allow you to use them so easily. Apart from the legal consequences, another hurdle you might encounter when fetching data from Facebook is the increasing difficulty of consistently accessing the information you need. Facebook is known to be vigilant in blocking suspicious IP addresses and might even tighten its blocking mechanisms further down the line. This could make scraping data from them nearly impossible for you. Therefore, exploring alternative social media data sources that offer greater reliability is strongly advised.

 GoLess Team
GoLess Team